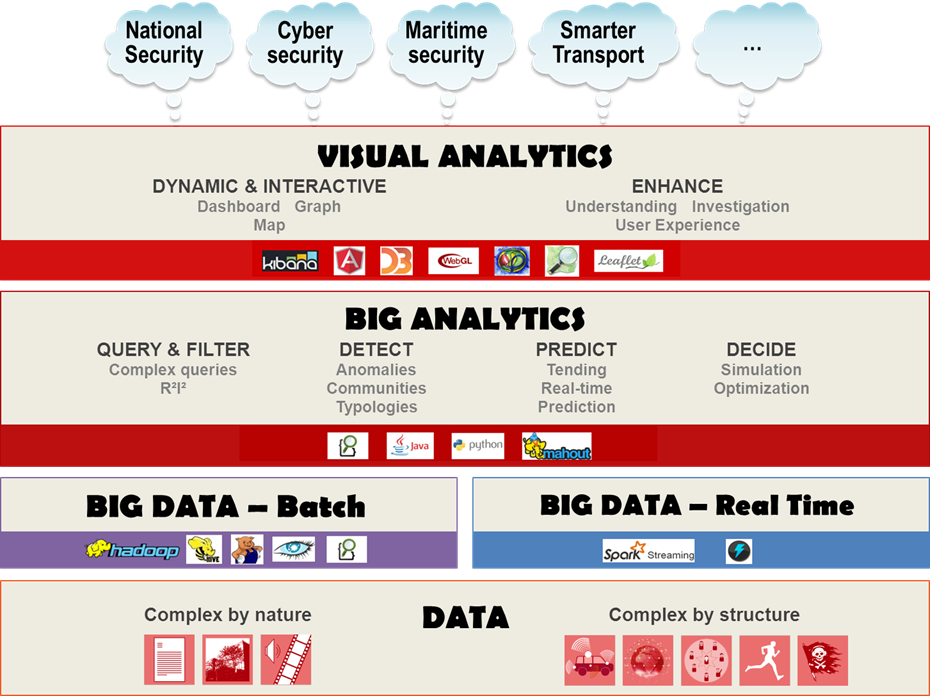
The Thales approach is structured around three closely interconnected themes: Big data (data management and storage), Big Analytics (processing, enrichment and value creation) and Visual Analytics (exploitation and interactive visualisation of datasets using parallelisable and/or linearisable analysis algorithms to ensure exhaustivity).
Never before in the history of the world has so much data been produced in such a short time. Smartphones, social media and mobile devices are responsible for much of it — but so are the ever-increasing numbers of security cameras, satellites, tags, sensors and wireless networks. New ways of storing data and new indexing architectures are needed as a matter of urgency. Under the leadership of the major Internet players (Google, Facebook, Amazon, Twitter, etc.), data storage processes have adapted to the growth in the volumes of data to be stored. NoSQL (Not Only SQL) database management techniques outperform current SQL relational database management solutions and are driving the emergence of a whole new approach to database architectures.
Big Analytics relies on algorithms, and different algorithms are needed for structured, unstructured and partly structured data.
If we know how the data is structured, statistical processes can be used to sample the datasets and draw conclusions from a smaller population without the need for exhaustive analysis of the often significant quantities of data available. This could be called “Big Analytics by extension” or “hypothesis-driven” analysis, because certain aspects of the analysed population (sub-classes, underlying distributions[1], etc.) are assumed to be true from the outset, making the computing operations much more straightforward. This is an extension of the data mining approach of the 1990s-2000s.
If we do not know exactly how the data is structured – as is typically the case with large distribution networks, communications networks and social networks, for example – it is nearly impossible to make assumptions before the analysis begins. In these cases, exhaustive analysis is required, meaning that the algorithms used need to be parallelised or linearised to achieve the level of scalability required to handle ever increasing volumes of data. This is referred to as a “data-driven” approach.
The classification into “data-driven” and “hypothesis-driven” approaches is a fundamental distinction, and one that transcends the typologies and terminology generally found in Big Analytics. Here we are in the realm of supervised and unsupervised learning, genetic algorithms and heuristic searches, artificial neural networks and relational clustering.
Through the CeNTAI laboratory, which is the focal point for the Group's Big data activities, Thales is developing both supervised learning algorithms (regression, decision trees, SVM, standard neural networks, expectation maximization, classification, etc.) and unsupervised learning algorithms (auto-encoders, clustering, copula theory, Markov chains, self-learning networks, etc.).
A generic platform has been set up has been set up at the CeNTAI lab, with a Big data architecture based on NoSQL and Elasticsearch to store and access large volumes of heterogeneous, dynamic data from information systems either in batch mode or real time, and Big Analytics and Visual Analytics algorithms primarily dedicated to data fusion, intelligent queries, type analysis, community detection, anomaly and weak-signal detection and investigation, predictive analysis and decision support.
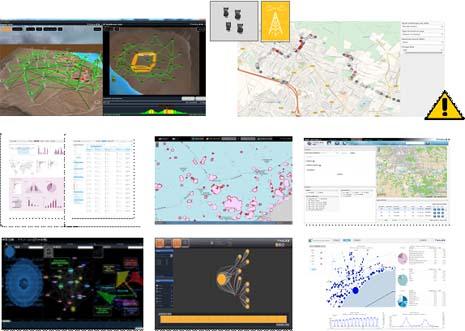
Thales is working with its customers to implement processing sequences for specific business areas, with a particular focus on cybersecurity, communication networks, maritime security, border control, electronic warfare and ground transportation.
[1] Gaussian or uniform distributions, etc.